
Ennek a cikknek a célja az, hogy áttekintést nyújtson az Mesterséges Intelligencia területéről a nagyközönség számára, azokat az olvasókat megcélozva, akik egyébként a médiából és a sajtóból szereznek információkat. Ezek a médiumok gyakran eltorzítják és túlzottan felnagyítják a Mesterséges Intelligencia bizonyos aspektusait, kihasználva a félelmet, bizonytalanságot és kételyeket, amelyeket az olvasók félreinformálásával terjesztenek. Beszélni fogunk az MI-vel kapcsolatos valódi veszélyekről is, amelyek eltérnek a médiában bemutatott veszélyektől. Most van itt az ideje annak, hogy az átlagember jobban megértse, hogy mivel néz majd szembe, és hogyan változtathatja meg az AI az életét a jövőben.
Miben hasonlít és miben különbözik az emberi és a mesterséges intelligencia?
Az utóbbi években egyre inkább összehasonlítás tárgyává vált az emberi és a mesterséges intelligencia. Az emberi intelligencia azon kognitív képességekre utal, amelyeknek az emberek birtokában vannak, mint például a problémamegoldás, a logikus gondolkodás, az észlelés és a kreativitás, míg az MI olyan gépek intelligenciájára vonatkozik, amelyek képesek szimulálni az emberi értelmet és döntéshozatalt. Bár mindkét intelligenciaforma rendelkezik saját erősségekkel és gyengeségekkel, az összehasonlításukkal kapcsolatos folyamatos vita azon kérdés körül forog, hogy az MI képes lesz-e valaha is túlszárnyalni vagy akár teljesen helyettesíteni az emberi intelligenciát minden területen. Érdemes ezért összehasonlítani őket, mivel sokkal több mindenben különböznek, mint azt a felületes szemlélő gondolná. Kezdjük talán az intelligencia fejlődésével. Az emberi intelligencia fejlődése mögött több motiváció is áll, amelyek az egyéni és a faj szintjén is jelentősek. Néhány fontos motiváció a következőkben foglalható össze:
- Túlélés és alkalmazkodás: Az evolúció során az intelligencia növekedése segített az embereknek jobban alkalmazkodni a környezetükhöz, megküzdeni a kihívásokkal és túlélni. Az értelmi képességek, mint a problémamegoldás, a tanulás és az emlékezet, lehetővé tették számunkra, hogy új stratégiákat dolgozzunk ki a túlélés érdekében.
- Szociális kapcsolatok és kommunikáció: Az emberi intelligencia fejlődésében a szociális kapcsolatok és a kommunikáció kulcsfontosságúak. A bonyolultabb társadalmi struktúrákhoz alkalmazkodás érdekében az embereknek fejlettebb kommunikációs képességekre és jobb empátiára volt szükségük egymás gondolatainak és érzéseinek megértéséhez.
- Eszközhasználat és technológiai fejlődés: Az intelligencia növekedése lehetővé tette az emberek számára, hogy új eszközöket és technológiákat fejlesszenek ki, amelyek megkönnyítették a mindennapi életet és növelték a túlélési esélyeket. A technológiai fejlődés hajtóereje az emberi kíváncsiság, az innováció és a folyamatos fejlődés iránti vágy.
- Verseny és társadalmi rang: Az emberi társadalmakban a verseny és a társadalmi rang szintén motiváló tényező az intelligencia fejlődésében. Az egyének versengenek egymással, hogy megszerezzék a legjobb erőforrásokat, a hatalmat és a társadalmi elismertséget, ami gyakran az intelligenciához és a képességekhez kötődik.
- Önmegvalósítás és kreativitás: Az intelligencia fejlődése lehetővé teszi az egyének számára, hogy kifejezzék önmagukat, új ötleteket alkossanak, és hozzájáruljanak a kultúra és a művészet fejlődéséhez. Az önmegvalósítás és a kreativitás vágya tovább ösztönzi az intelligencia növekedését és a képességek fejlesztését.
Ezek a motivációk összefonódnak és kölcsönhatásba lépnek egymással az emberi intelligencia fejlődése során. További motivációs tényezők is befolyásolhatják az intelligencia fejlődését, mint például:
- Nevelés és oktatás: A családi és oktatási környezet fontos szerepet játszik az intelligencia fejlődésében. A korai években a szülők és nevelők támogatása, valamint a minőségi oktatás hozzáférhetősége növelheti az egyének intelligencia fejlődését és ösztönözheti a tanulás iránti vágyat.
- Kihívások és akadályok: Az élet során tapasztalt kihívások és akadályok arra ösztönözhetik az embereket, hogy fejlesszék intelligenciájukat és problémamegoldó képességeiket. A nehézségek leküzdése gyakran új képességek elsajátítására és a meglévő képességek fejlesztésére ösztönöz.
- Környezeti hatások: A környezeti hatások, mint például a társadalmi-gazdasági helyzet, a kulturális hátterek és az életkörülmények, szintén befolyásolják az intelligencia fejlődését. Az egyének, akik megfelelő környezetben nőnek fel, nagyobb eséllyel fejlődnek az intelligencia terén.
- Ösztönzés és elismerés: A pozitív megerősítés, az ösztönzés és az elismerés mind hozzájárul az intelligencia fejlődéséhez, mivel ezek segítenek az egyéneknek abban, hogy magabiztosabbak legyenek és hajlamosabbak legyenek kipróbálni új dolgokat, új képességeket elsajátítani és fejleszteni.
Ezen motivációk és tényezők kombinációja segíti és ösztönzi az emberi intelligencia fejlődését az egyén és a faj szintjén is. Az intelligencia fejlődése állandó folyamat, amely a genetikai, környezeti és társadalmi tényezők összjátékának eredménye. Amellett, hogy ezek a tényezők hozzájárulnak az intelligencia fejlődéséhez, meg is határozzák annak preferenciáit - tehát célokat, vágyakat adnak az embereknek, amelyek érdekében használni kívánja majd az intelligenciáját, amelyek érdekében cselekedni fog.
Ezzel szemben a mesterséges intelligencia esetében nem határozhatók meg hasonló motivációs tényezők, legalábbis olyanok biztosan nem, amelyek az összes MI esetében általánosan érvényesek lennének. A motiváció fogalma elsősorban emberi viselkedésre vonatkozik, és arra, hogy az emberek miért és hogyan cselekszenek bizonyos körülmények között. Mesterséges intelligenciák, mint például a ChatGPT, nem rendelkeznek emberi érzelmekkel vagy személyes motivációval. Egy MI rendszer "motiválttá" tétele nem azonos az emberi motivációval. Viszont a rendszer teljesítményének javítása érdekében lehetőség van arra, hogy úgy alakítsuk és fejlesszük az MI-t, hogy hatékonyan és pontosan válaszoljon a felhasználói igényekre. Például a fejlesztők maximalizálhatják a teljesítményt és hatékonyságot a felhasználói interakciók során, akár egyszerűen a felhasználói élmény javítása érdekében, akár egy előre kiválasztott, jól meghatározható cél mentén. Egy MI rendszer "motiválttá" tétele a következő módszerekkel érhető el:
- Célirányos tanítás: Az MI tanítása során biztosítani kell, hogy a rendszer megfelelő adathalmazokból tanuljon. Az adatoknak reprezentatívnak, változatosnak és magas minőségűnek kell lenniük, hogy az MI képes legyen megérteni és reagálni a felhasználói igényekre.
- Jutalmazási rendszerek: Egy mesterséges intelligencia "motivációját" úgy is befolyásolhatjuk, hogy meghatározott célkitűzéseket teljesítve jutalmakat kapjon. Ezáltal az MI rendszer azonosíthatja a helyes viselkedést, és ösztönözve lesz a hasonló megoldások alkalmazására. Ez hatásában hasonló az emberi agy jutalmazási rendszeréhez, ahol ez a folyamat különböző ingerületátvivő hormonok, neurotranszmitterek (pl. dopamin, szerotonin, oxytocin és az endorfinok) segítségével történik.
- Finomhangolás: Az MI rendszer rendszeres finomhangolást és felülvizsgálatot igényel, hogy javítsuk a teljesítményét és alkalmazkodóképességét a változó felhasználói igényekhez. Ez magában foglalja a hibák és hiányosságok kijavítását, valamint az új adatokból való tanulást.
- Visszajelzés: A felhasználóktól érkező visszajelzések alapján az MI rendszert folyamatosan frissíteni és javítani kell. A felhasználói visszajelzés segíthet az MI fejlesztőinek abban, hogy jobban megértsék, milyen területeken van szükség fejlesztésre.
Az emberi és a mesterséges tudat
Az emberi tudat még ma is aktív kutatási területe a pszichológiának és az orvostudománynak, annyit viszont mindenképp elmondhatunk róla, hogy szorosan kötődik az emberi intelligencia evolúciós fejlődését motiváló tényezőkhöz, mint például a túlélésre vagy a fajfenntartásra irányuló vágyak, kényszerek. Gondolatainkat közvetve vagy közvetlenül nagyon gyakran meghatározzák ezek a motivációk, és az általunk tapasztalt tudat is valahol ezek eredőjeként jön létre, és ez nagy hatással van az etikai érzékünkre, érzelmeinkre és lelkiismeretünkre. Ehhez hasonló vágyai vagy kényszerei a mesterséges intelligencia rendszereknek nincsenek. A mesterséges intelligencia jelenleg csak arra képes, hogy nagyon élethűen tudja azt az érzést kelteni, hogy tisztában van az általa statisztikai módszerekkel generált szöveg kontextusával. De ez a kontextus még csak nem is hasonlítható ahhoz a kontextushoz, ami az ember fejében létezhet.
Egy nagyon egyszerű példa lehet egy olyan esszé megírása, amelyben az MI azt az érzést kelti, hogy tökéletesen tisztában van azzal, hogy az ember és az őt körülvevő világ apró részecskékből, úgynevezett atomokból áll. Ilyenkor az ember fejében - iskolázottságtól függően - valóban megjelennek apró 3 dimenziós objektumok azaz atommagok, amelyek körül elektronok keringenek, esetleg magasabb szinten térben és időben változó mezők, amelyekben apró rezgések, hullámok alkotják az általunk ismert részecskéket. Ezeket az ember képes szavak használata nélkül is, 3 dimenziós projekcióként elképzelni. Az MI által érzékeltetett kontextus viszont csak szintaktikai, tehát mindössze szavakra korlátozódik, nincsenek a memóriájában kész 3 dimenziós modellek arról, hogy hogyan is néz ki valójában az atomok és molekulák világa. Miközben jelen cikk írója ezt a szöveget megfogalmazza, maga is tisztában van olyan fogalmakkal, mint a részecskék világának eddig feltárt sztenderd modellje, a kvarkok és glüonok világa, az általuk létrejövő bonyolultabb részecskék, mint mezőkben képződő hullámcsomagok absztrakciói. Ehhez fogható modellek nem élnek a jelenleg kifejlesztett mesterséges intelligencia modellek memóriájában – bár nem is zárja ki semmi azt, hogy az MI fejlődésével olyan rendszerek is létrehozhatók, amelyek erre is képesek lesznek. Ettől viszont szerintem még nagyon messze vagyunk.
Nem véletlen talán az, hogy a jelenlegi transzformatív modellek eredeti feltalálója a Google eredetileg még nem érezte késznek a saját architektúráit arra, hogy a szélesebb publikummal is megismertesse azokat úgy, ahogy végül azt az OpenAI tette a ChatGPT-vel. Hiszen ezek az architektúrák a szöveg generálása közben sajnos hallucinálnak is, és ezen hallucinációk részben pontosan a fentiekben említett kontextusbeli különbségeknek, hiányosságoknak köszönhetők. További kutatásokra, rengeteg munka befektetésére van még szükség ahhoz, hogy a generatív rendszerek valóban az emberiség tudásbázisának, ismereteinek megfelelő, azzal ekvivalens kontextusokat tudjanak tárolni, miközben szöveget (vagy képet, zenét, bármilyen mérnöki vagy művészeti alkotást) generálnak. Ez minimálisra csökkentené a hallucinációk mennyiségét is. Jelenleg viszont még csak akkor hasznosítható az MI által generált szöveg, ha azt egy valódi emberi intelligenciával rendelkező résztvevő is utólag lektorálta és jóváhagyta.
Mesterséges hallucinációk
A hallucináció az utóbbi évek egyik újonnan felkapott technológiai szlogenje, gyakran találkozhatunk ezzel a kifejezéssel a generatív Mesterséges Intelligencia kontextusában. Mesterséges hallucinációként beszélünk az olyan gépi tanulási modellek által előállított mintákról, képekről vagy kimenetekről, amelyek nem feltétlenül korrelálnak a valósággal. Ez a jelenség gyakran akkor fordul elő, amikor egy MI modellt arra kényszerítünk, hogy túlmutasson a képzési adatainak határain vagy bonyolultságán. Lényegében a gép 'kitalál' tartalmat, egy olyan formáját hozva létre a gépi észlelésnek, amely eltér az emberi világértelmezéstől. Ez a jelenség elmosódást hoz létre a gépi észlelés és a valóság között, izgalmas kérdéseket vet fel a mesterséges kogníció természetéről és kapacitásáról.
Mesterséges hallucinációk a Generatív Ellenséges Hálózatokban (GAN) is előfordulnak, amelyek egy olyan MI modell típust képviselnek, amelyet új tartalom létrehozására használnak. A GAN-eket olyan realisztikus kinézetű képek létrehozására használják, amelyek nem létező embereket ábrázolnak. Ezek az MI által előállított alkotások, bár néha hihetetlenül pontosak, váratlan és hallucinációs kimeneteket is eredményezhetnek.
Gyakorlati szinten a mesterséges hallucinációk kihívást jelentenek az MI fejlesztés számára. Vezethetnek félreértelmezésekhez vagy hibákhoz különösen kritikus területeken, mint például az autonóm vezetés, ahol egy tárgy téves azonosítása végzetes következményekkel járhat. A mesterséges hallucinációk megértése és csökkentése így az MI biztonságának és megbízhatóságának alapvető kutatási területe.
Filozófiai szinten a mesterséges hallucinációk kihívást jelentenek az észlelés és a kogníció fogalmának értelmezésében. Ha egy MI képes arra, hogy tartalmat 'álmodjon' vagy 'hallucináljon', mit jelenthet ez a gépi kogníció értelmezésében? Lehet-e a gépeknek saját szubjektív tapasztalataik? Bár a mesterséges hallucinációk nem adnak végleges válaszokat ezekre a kérdésekre, minden bizonnyal termékeny talajt biztosítanak a filozófiai vizsgálódáshoz.
A Mesterséges Intelligencia gerince, a Neurális Hálózat
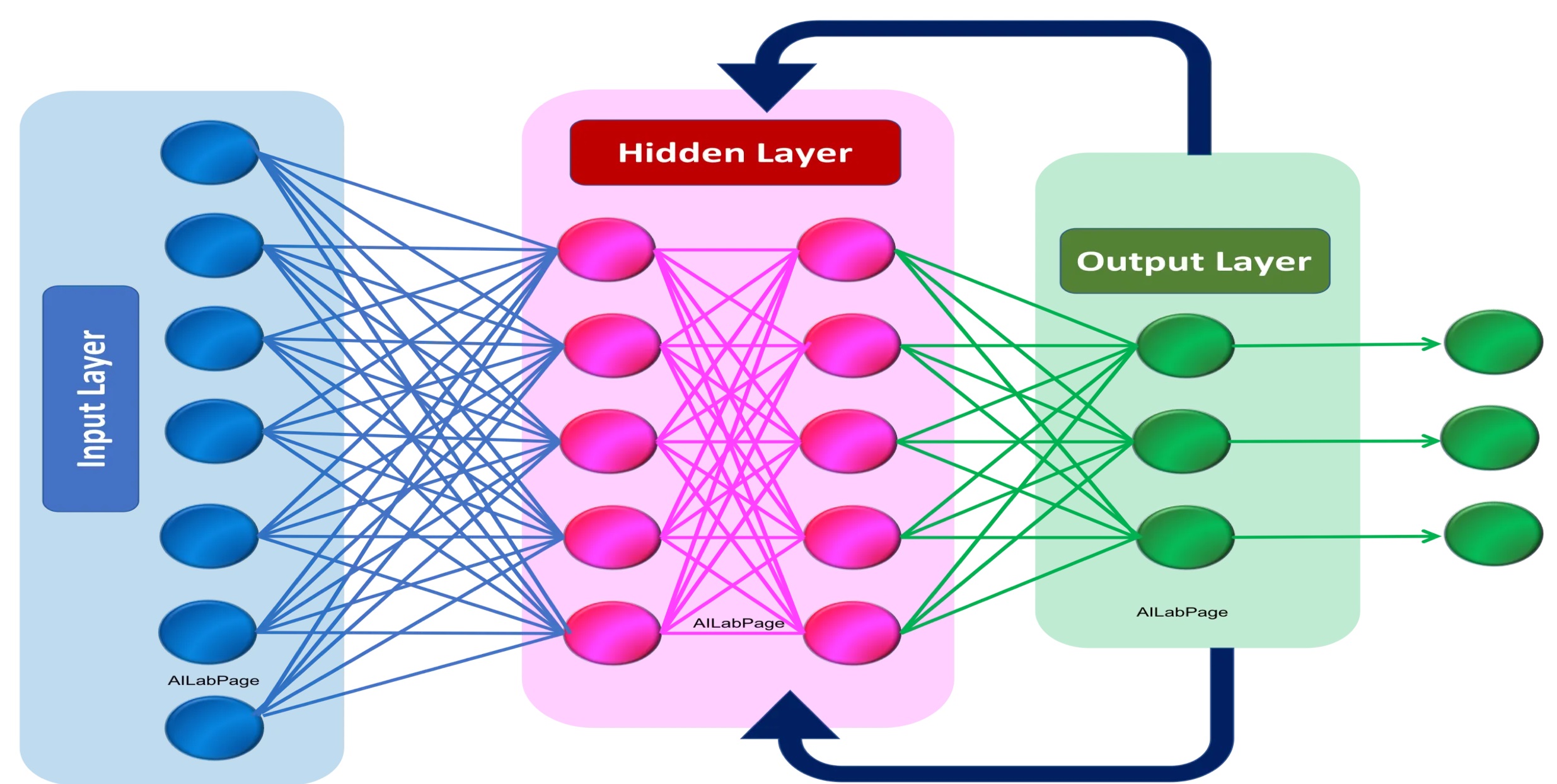
A mesterséges intelligencia technológiáinak egyik fontos építőköve az úgynevezett előre csatolt neurális hálózat. Ez egy olyan mesterséges neurális hálózat típus, amely az emberi agy információfeldolgozó folyamatát próbálja utánozni. Lényegében egy olyan számítási modellről van szó, amely bemeneti adatokat fogad, feldolgozza azokat több rétegnyi mesterséges neuronon keresztül, és kimenetet generál. Ezeket a hálózatokat előre csatoltnak hívják, mivel az információ egy irányban, a bemenettől a kimenetig, ciklusok nélkül halad.
A legjobb, ha a neurális hálózatot fekete dobozként képzeljük el. Ennek a fekete doboznak vannak bemenetei és kimenetei. Inicializálatlan állapotban ennek a doboznak teljesen meghatározatlan a viselkedése: tetszőleges válaszokat ad bármilyen bemenetre (bár mindig ugyanazokat a válaszokat adja ugyanazokra a bemenetekre). Képzeljük el, hogy ennek a doboznak a kezdeti állapota a teljes rendezetlenség (avagy legmagasabb entrópia); még nem történt erőfeszítés, hogy azt tegye, amit elvárunk tőle. Ez az állapot analóg lehet egy újszülött csecsemő agyával – éppen most kezdi megtapasztalni az őt körülvevő világot. (A fekete doboz hasonlatot itt leginkább a hálózat súly és eltolás paramétereire értjük, nem pedig a hálózat működésére. A hálózat működését természetesen ismerjük és értjük. A paramétereket viszont nekünk nem szükséges explicite ismernünk, azokat a hálózat saját magától képes úgymond “megtanulni”.)
Van egy felügyelt tanulásnak nevezett folyamat, amelynek során a dobozt bemeneti-kimeneti mintákkal táplálják, és a belső entrópiáját csökkentik azáltal, hogy megtanulja a bemenetek és a kimenetek közötti kapcsolatokat. A tanulási folyamat azzal kezdődik, hogy a bemeneteinket betápláljuk az inicializálatlan dobozba, és összehasonlítjuk a kívánt kimeneteket a ténylegesekkel. Először valószínűleg nagy különbséget fogunk kapni, mivel a doboznak fogalma sincs az elvárt bemenet-kimenet kapcsolatokról. Ezt a különbséget a neurális hálózat hibájának nevezzük. A betanítási folyamat során az a célunk, hogy ezt a hibát a lehető legkisebbre csökkentsük úgy, hogy ugyanazokat az bemenet-kimenet mintákat iteratív módon újra és újra betápláljuk, és ekkor a doboz úgy módosítja a belső állapotát, hogy annak az általános hibája (avagy entrópiája) csökkenjen.
Építőelemek: a Neuronok
Az előre csatolt neurális hálózat alapvető építőeleme a mesterséges neuron, amelyet csomópontnak vagy perceptronnak is neveznek. Ez egy egyszerű feldolgozó egység, amely több bemenetet fogad, matematikai függvényt alkalmaz rájuk, és egy kimenetet állít elő. A neuron célja, hogy mintákat találjon és tanuljon a bemeneti adatokból.
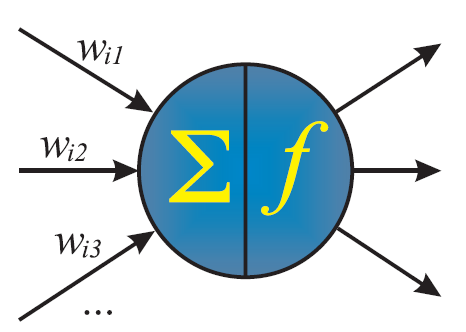
A mesterséges neuron
Az előre csatolt neurális hálózatok rétegekben vannak strukturálva, minden réteg több neuront tartalmaz. Háromféle réteg van:
- Bemeneti réteg: Ez az első réteg, ahol a hálózat bemeneti adatokat kap. Ezen réteg minden neuronja a teljes adathalmaz egy dimenzióját képviseli.
- Rejtett rétegek: Ezek a bemeneti és kimeneti rétegek közötti rétegek. Feldolgozzák a bemeneti adatokat, és segítenek a hálózatnak bonyolult minták tanulásában. Egy neurális hálózatnak több rejtett rétege is lehet.
- Kimeneti réteg: Ez a végső réteg, ahol a hálózat kimenetet generál. Ebben a rétegben lévő neuronok száma megfelel a lehetséges kimeneti értékek számával.
- Egy rétegen belül a neuronok nem állnak kapcsolatban egymással.
- Egy rejtett réteg összes neuronja kapcsolatban áll az azt követő és az azt megelőző réteg összes neuronjával, úgynevezett súly értékeken keresztül. Két réteg neurális kapcsolatait ezért lényegében egy 2 dimenziós mátrixszal tudjuk modellezni, amelyet súlymátrixnak is neveznek.
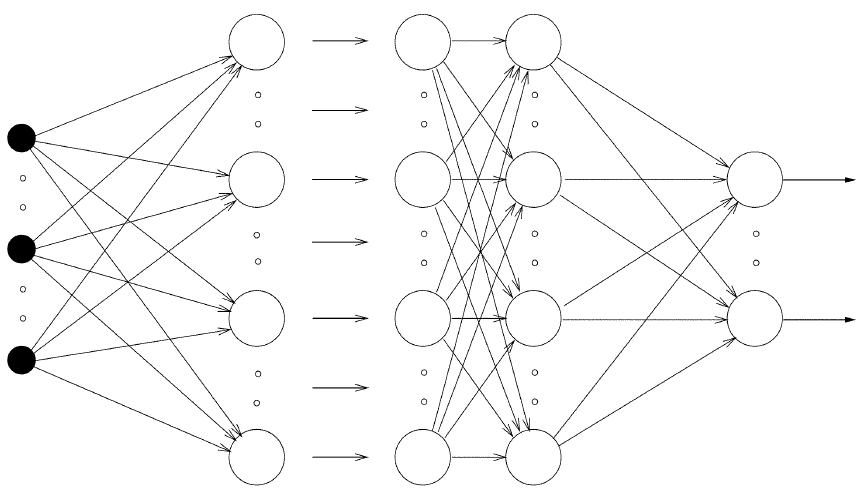
Mesterséges Neurális Hálózat
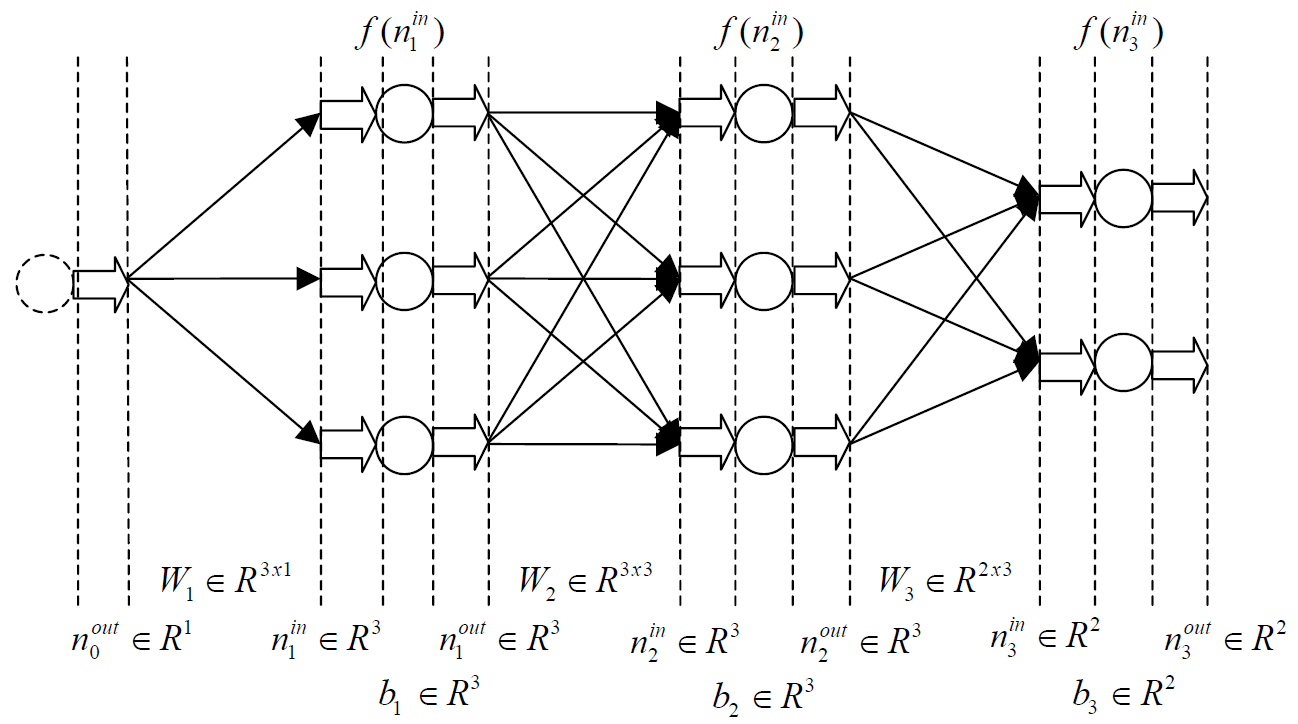
Mesterséges Neurális Hálózat modellezése mátrixok segítségével. A ‘W’ mátrixok a súlyok (weights) mátrixai, a ’b’ vektorok pedig az eltolások, azaz a bias-ok vektorai.
Összekötő elemek: Súlyok és eltolások
Az előre csatolt neurális hálózat neuronjai súlyok és eltolások rendszerén keresztül kapcsolódnak össze. A súlyok számszerű értékek, amelyek a neuronok közötti kapcsolatokhoz vannak hozzárendelve, meghatározva az egyes bemenetek fontosságát. Az eltolások viszont konstansok, amelyeket a súlyozott bemenethez adnak, lehetővé téve a neuron számára a pontosabb előrejelzések készítését.
A tanulási folyamat során a hálózat úgy igazítja a súlyokat és eltolásokat, hogy minimalizálja az előrejelzések és a tényleges kimenet közötti különbséget. Ezt egy visszaterjesztés (backpropagation) nevű technikával érik el, amely a hiba kiszámítását és a súlyok és eltolások ennek megfelelő frissítését foglalja magában.
A mesterséges neuronok és az aktivációs függvények
Az aktivációs függvények kulcsfontosságú szerepet játszanak a neurális hálózatokban, mivel úgynevezett nemlinearitást vezetnek be a hálózatba. Ez a nemlinearitás lehetővé teszi a neurális hálózatok számára, hogy összetett kapcsolatokat modellezzenek a bemeneti adatok és a kimeneti előrejelzések között. A mesterséges neuron lényegében egy szűrőként működik, amelyet az úgynevezett aktivációs függvénnyel valósítanak meg. Ha a bemenetek összegzett jelszintje azaz értéke elér egy bizonyos határt, akkor a neuron továbbítja a jelét a következő réteg neuronjai felé. Ha viszont a bemenetek nem érik el ezt a szintet, a neuron nem továbbít jelet (vagyis a mesterséges neuron esetében nullát, vagy csak egy konstans eltolás értéket továbbít). Néhány ismert aktivációs függvény:
- Szigmoid függvény: A szigmoid függvény a bemeneti értékeket 0 és 1 közé szorítja. Széles körben alkalmazzák bináris osztályozási feladatokra, azonban a tanulás során szenvedhet az eltűnő gradiens problémától. Ez akkor jelentkezik, amikor sok rejtett rétegű hálózatot tanítunk, és a visszaterjesztés során - ahogy haladunk a kimeneti réteg felől a bemeneti réteg felé - a számított delta (módosító avagy gradiens) értékek egyre kisebbek és kisebbek lesznek. Ezek az értékek akár nullává is válhatnak, ami azt jelenti, hogy a hálózat ekkor abbahagyja a tanulást.
- Hiperbolikus tangens (tanh) függvény: A tanh alakja megegyezik a szigmoid függvény alakjával, de az értékeket -1 és 1 közé képezi le. Kiegyensúlyozottabb a szigmoid függvénynél, mivel nulla körül központosított.
- Javított lineáris egység (ReLU) függvény: A ReLU függvény népszerű választás lett egyszerűsége és az eltűnő gradiens probléma enyhítésére való képessége miatt. Pozitív bemeneti érték esetén visszaadja azt, egyébként pedig nullát ad eredményül.
- Szivárgó ReLU: A ReLU függvény változata, a Szivárgó ReLU engedélyez egy kis, nem nulla gradienst a negatív bemeneti értékekhez, kezelve ezzel a "halott neuronok" problémáját, amely a szokásos ReLU esetén előfordulhat.
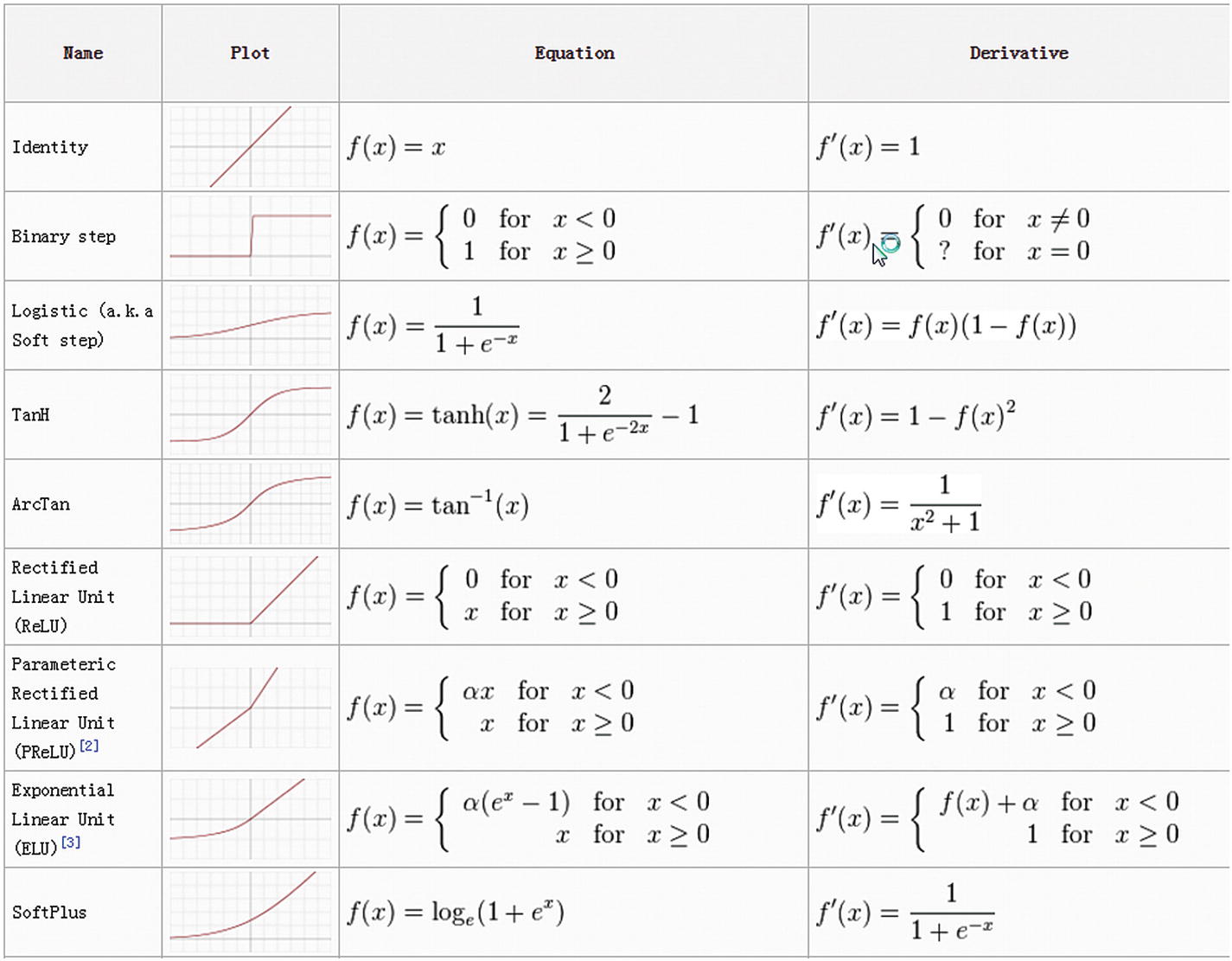
A fontosabb ismert aktivációs függvények és azok deriváltjai
Neurális Hálózatok tanítása, a visszaterjesztés (backpropagation) algoritmus
Ha több réteg van egy neurális hálózatban, akkor a belső rétegeknek nincsenek elvárt értékeik, sem pedig hibáik. Ez a probléma megoldatlan maradt egészen a 1970-es évekig, amikor a matematikusok felfedezték, hogy a visszaterjesztés algoritmus használható erre a különös problémára.
A hátraterjesztés módszere lehetővé teszi neurális hálózatok bármennyi rejtett réteggel történő tanítását. Először az algoritmus kiszámítja az utolsó réteg hibáját, ami egyszerűen a kimenet és a célértékek közötti különbség. Ezután visszaterjeszti ezt a hibát a hálózat rejtett rétegeibe az aktivációs függvények deriváltjának felhasználásával. Így a hálózat képes lesz a rejtett rétegek neuronjainak a hibáit is kiszámítani, amelyekhez nincs rendelkezésre álló tanító adat. Miután ezeket a hiba értékeket kiszámították, a hálózat súlyait és eltolásait úgy módosítják, hogy ezek a hibaértékek csökkenjenek. Ha ezt a módszert többször megismételve alkalmazzák a hálózaton, akkor a hálózat hibája elkezd csökkenni, amíg olyan kimeneteket nem ad, amelyek nagyon közel állnak a elvárt értékekhez.
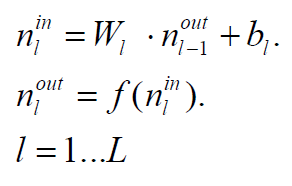 Előre terjesztés mátrix műveletekkel
Előre terjesztés mátrix műveletekkel
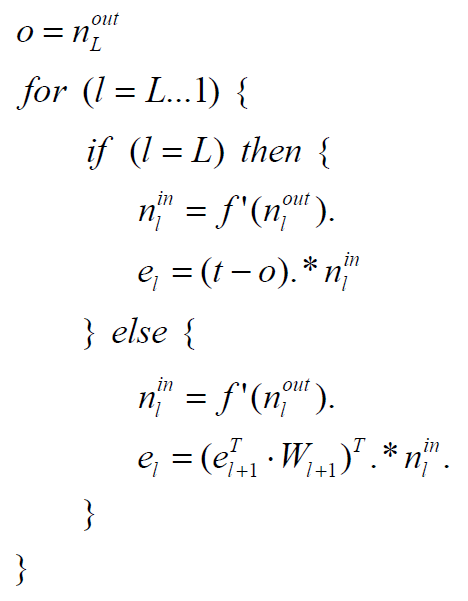 A visszaterjesztés algoritmus egy iterációja mátrix műveletekkel
A visszaterjesztés algoritmus egy iterációja mátrix műveletekkel
Regularizációs technikák
A regularizációs technikák célja, hogy megakadályozzák a neurális hálózatok túltanulását úgy, hogy egy büntető tagot adnak hozzá a veszteség függvényhez. A veszteség függvény a teljes hálózat állapotára jellemző értéket határoz meg, attól függően, hogy mi a célunk a hálózat tanításával. Ha regresszióra tanítjuk a hálózatot, akkor a hálózat hibájának a négyzete lesz a veszteség függvény. Osztályozási probléma esetén az úgynevezett keresztentrópia (cross entropy) függvényt használjuk a veszteség kiszámítására. A túltanulás akkor következik be, amikor a modell túl jól tanulja meg a tanító adatokat, zajt és pontatlanságokat rögzítve, nem pedig az alapvető mintázatokat. Néhány ismert regularizációs technika:
- L1 és L2 regularizációk: Az L1 és L2 regularizációs technikák büntető tagot adnak a veszteség függvényhez, arányosan a modell súlyainak abszolút értékeinek összegével (L1), vagy négyzetes értékeinek összegével (L2). Ez arra ösztönzi a modellt, hogy kisebb súlyokat alkalmazzon, egyszerűbb és általánosabban alkalmazható modelleket eredményezve.
- Kiesés (Dropout): A kiesés olyan technika, amelyben a neuronok véletlenszerű részhalmaza "kiesik" vagy ideiglenesen inaktívvá válik a képzés során. Ez megakadályozza, hogy a modell túlságosan támaszkodjon az egyes neuronokra, elősegítve egy szétosztottabb és robosztusabb reprezentációt.
- Korai leállítás (Early stopping): A korai leállítás során a modell teljesítményét egy validációs halmazon figyelik, és leállítják a képzési folyamatot, amikor a teljesítmény romlani kezd. Ez megakadályozza, hogy a modell túltanulja a tanító adatokat, mivel a tanulási folyamatot leállítja, mielőtt a modell túl bonyolulttá válna.
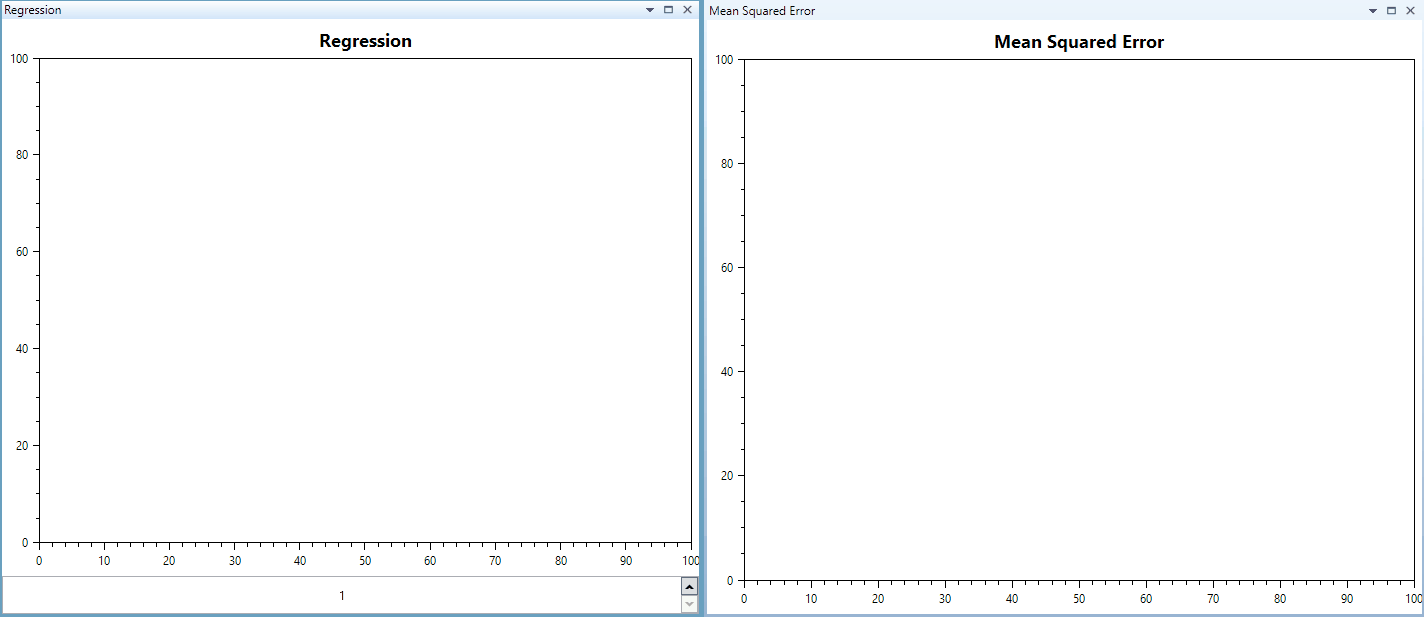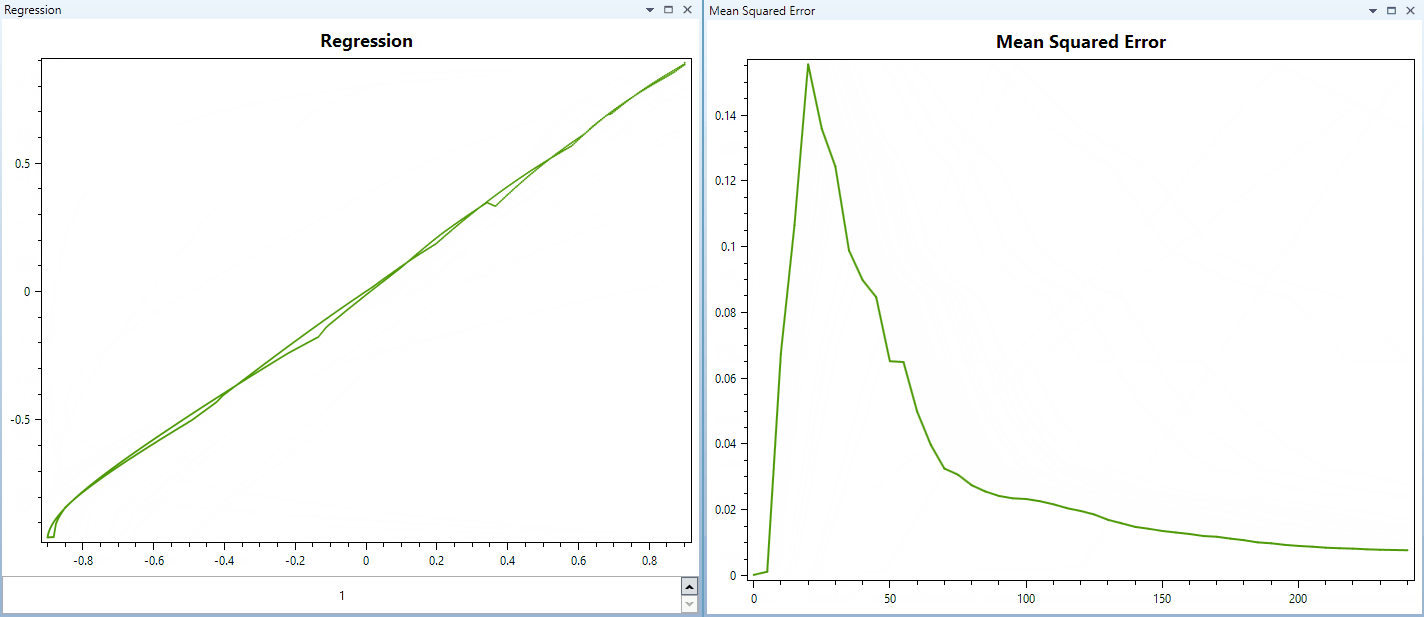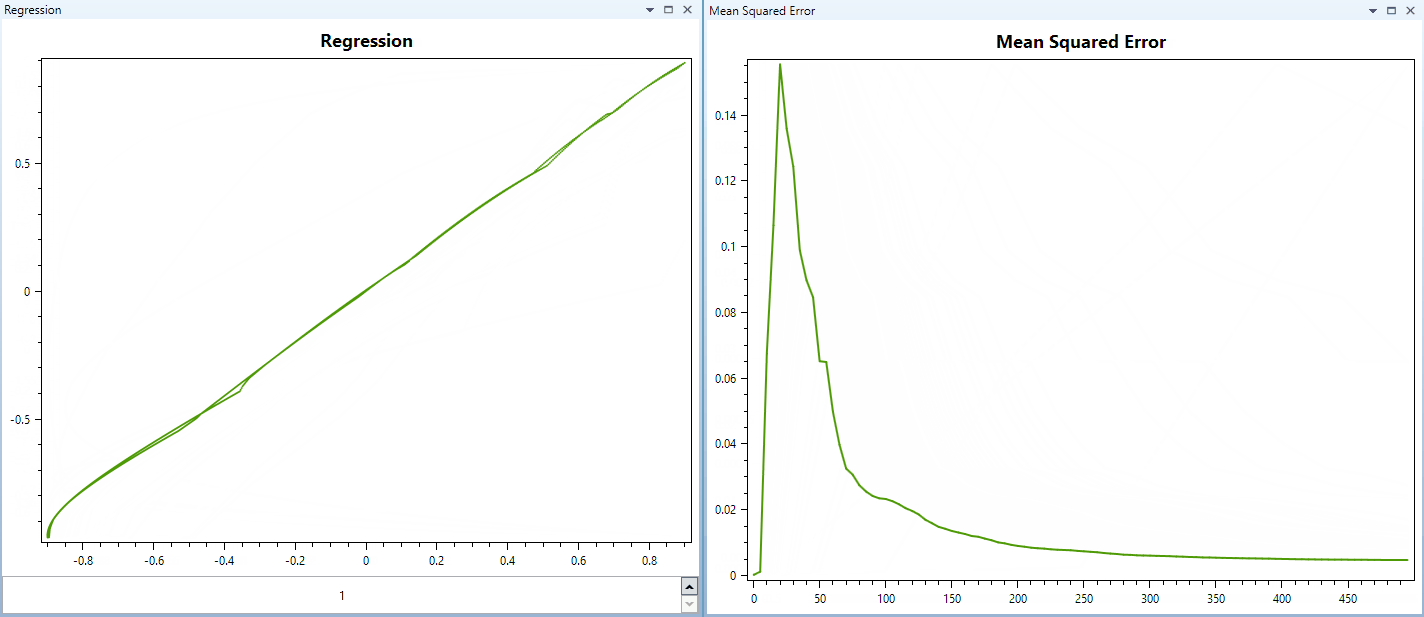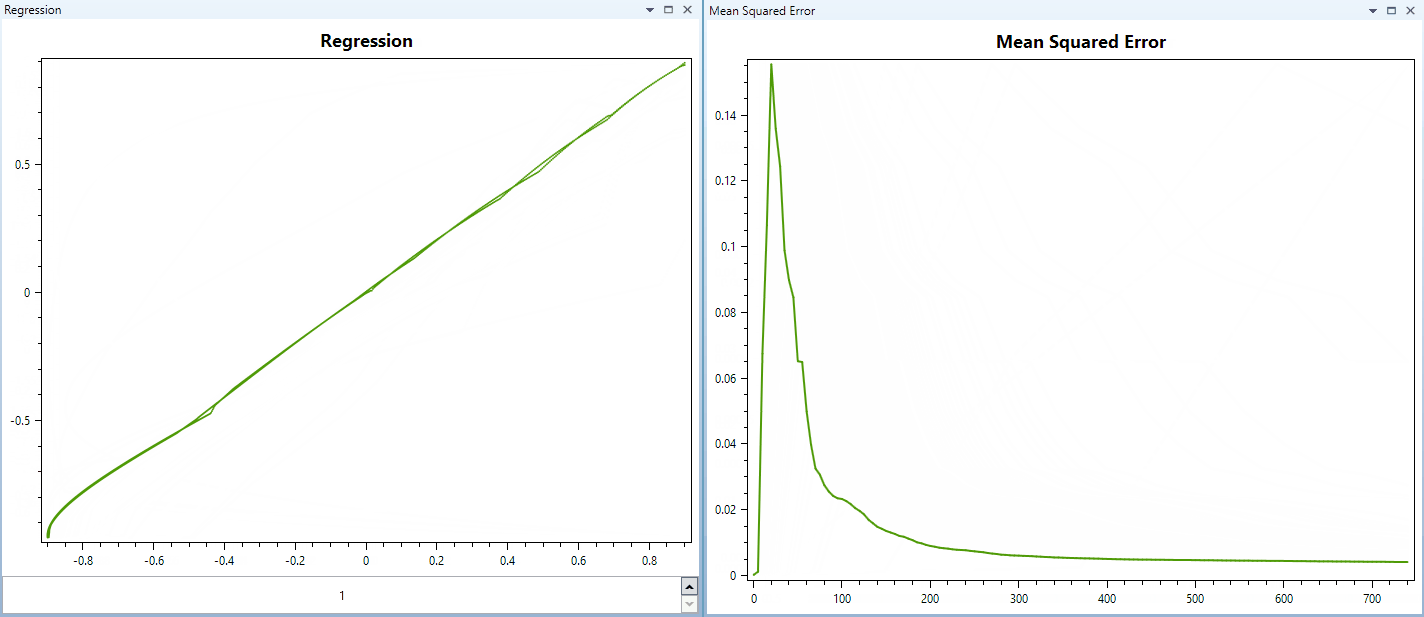
Neurális Hálózat tanítási folyamata iterációkon keresztül. Itt a hálózat egy egyszerű kvadratikus függvényt tanul éppen. A regresszió grafikon az aktuális kimenetet ábrázolja az elvárt kimenet függvényében.
A konvolúciós neurális hálózatok (CNN-ek)
A konvolúciós neurális hálózatok (CNN-ek) speciális típusú hálózatok, amelyeket pixeles adatok, például képek feldolgozására terveztek. Így az előrecsatolt neurális hálózatokat képfelismerési feladatokra is alkalmazni lehet, a CNN-eket kifejezetten erre a célra tervezték. A CNN-ek konvolúciós rétegeket tartalmaznak, amelyek szűrőket használnak a bemeneti adatokban lévő helyi jellemzők felismerésére. Ezeket a szűrőket az egész bemeneten osztják meg, csökkentve a paraméterek számát és hatékonyabbá téve a hálózatot.

Konvolúciós Neurális Hálózat
A rekurrens neurális hálózatok (RNN-ek)
A rekurrens neurális hálózatokat (RNN) szekvenciális adatok, mint például idősorok vagy szöveg feldolgozására tervezték. Az előre csatolt neurális hálózatoktól eltérően az RNN-ek olyan kapcsolatokkal rendelkeznek, amelyek visszacsatolnak önmagukra, lehetővé téve a szekvencia korábbi bemenetei "memóriájának" fenntartását. Ez a tulajdonság lehetővé teszi az RNN-ek számára, hogy megragadják az adatok időbeli függőségeit, így alkalmasak nyelvi modellezésre, beszédfelismerésre és idősor-előrejelzésekre. Például egy kódoló-dekódoló architektúra előre csatolt neurális hálózatot használhat a bemeneti szekvenciák rögzített hosszúságú reprezentációjává történő kódolására, amelyet aztán egy RNN-nek adnak át a kimeneti szekvencia előállításához.
Rekurrens Neurális Hálózat
A neurális hálózatok implementációja során felmerülő technológiai kihívások
A neurális hálózatok tanítása szerencsére párhuzamosítható, első körben a tanításra használt adatok felosztásával úgynevezett adatorientált párhuzamosítás hozható létre. Itt minden egyes feldolgozó egység (CPU, vektorprocesszor vagy speciális műveletvégző egység) a tanítandó adatoknak csak egy részhalmazát kapja meg, aztán a kapott eredményeket (a súlyokat módosító delta értékeket) minden lépés után összegzik. Ezzel a felosztással csak egy bizonyos szintig skálázható az algoritmus, ezért további párhuzamosítási technikákra van szükség.
Egy neurális hálózat esetében a legszámításigényesebb művelet az előre terjesztés és a visszaterjesztés során is alkalmazott mátrix szorzás. Előre terjesztéskor két réteg neuronjai között a súlyok mátrixát kell szorozni a neuronok kimeneteinek mátrixával, visszaterjesztéskor pedig a számított hibaértékek mátrixát a súlyok mátrixával. Ezek a műveletek rendkívül számításigényesek. Viszont az eredménymátrix értékei csak a szorzandó mátrixok bizonyos celláitól függenek, így ezek párhuzamosan is elvégezhetők. Még hatékonyabb lehet a párhuzamosítás, ha felbontjuk a mátrixokat 2x2-es, 4x4-es, 8x8-as vagy 16x16-os részmátrixokra, és ezeket a részmátrixokat úgynevezett SIMD módszerrel szorozzuk össze. Ezzel a módszerrel a processzor egy órajel ciklus alatt képes 8 vagy 16 lebegőpontos szorzást és összeadást elvégezni. Még hatékonyabb, ha speciális célhardvert vagy erre a célra kifejezetten alkalmas grafikus kártyát használunk, amelynek vannak úgynevezett tenzor magjai. Ezek a magok lényegében egy szorzást és összeadást hajtanak végre, és képesek egyidejűleg működni. Tehát 1000 tenzor mag esetén 1000 szorzás és összeadás művelet végezhető el egy ciklus alatt.

Mátrixok szorzása és összeadása tenzor mag segítségével
Érdemes megemlíteni, hogy nagyon sok alkalmazás esetében felesleges a neurális hálózatot 32 bites lebegőpontos számokkal modellezni, mivel 16 bites pontossággal is megfelelő eredményeket tudnak nyújtani. Ezért az újabb grafikus kártyák, valamint szerver processzorok már bevezették az úgynevezett félpontosságú lebegőpontos értékeket és az azokon végzett műveleteket.
Transzformer architektúra és generatív rendszerek
Mostanában nagy visszhangot kaptak a Transformer architektúrájú generatív nyelvi rendszerek, mint például a ChatGPT. Ezt az architektúrát eredetileg természetes nyelvek fordítására hozták létre, de azóta sok más területen is alkalmazzák. Korábban fordításra kódoló-dekódoló architektúrájú rekurrens (vagyis visszacsatolásos, RNN) neurális hálózatok voltak a legsikeresebbek. Itt a bemeneti nyelvre hangolt visszacsatolásos hálózat a lefordítandó szövegből előállított egy belső reprezentációt, melyet a másik nyelvre hangolt dekódoló hálózat (szintén visszacsatolásos) alakított át egy másik nyelvű szöveggé. A visszacsatolás gyakorlatilag szavanként történt, vagyis a kódoló komponensnek a szavanként beadott lefordítandó szövegre adott kimenetet (az előállított belső reprezentációt) a következő menetben hozzáadták a bemenethez, az újabb szóval együtt. Így a hálózatba újra és újra visszaforgattak valamit az előző szavakra produkált válaszból, így egyfajta memóriával rendelkezett a szövegkörnyezetre vonatkozólag. Ugyanez történt a dekódoló oldalon, viszont itt az újabb és újabb visszacsatolásos menetek alkalmával újra visszaforgatták a korábbi kimeneteket, melyek összefűzve adták a lefordított szöveget.
Ennek a megoldásnak komoly hátránya volt, hogy a korábbi szavak hatása idővel elhalványult. Erre született megoldásként a figyelem mechanizmus (attention mechanism), amely hagyományos memóriában őrzi az összes korábbi szó feldolgozási eredményét, és az újabb és újabb iterációk során nem az összes korábbi szó hatását veszi figyelembe, hanem csak a legfontosabbakét. (Hogy mely szavak esetén mely más szavak a legfontosabbak, azt szintén a betanítás során tanították meg a hálózattal.) Ez a figyelem mechanizmus a visszacsatolásos módszert váltotta le, és ezzel lehetőséget adott még hatékonyabb párhuzamos feldolgozásra.
Ezután jelent meg a csak dekódoló komponenst használó változat, amely már nem fordításra szolgált, hanem szöveg folytatására. A különbség lényegében annyi, hogy a betanítás során egy adott szövegnek nem egy másik nyelvű változatára tanítják be a rendszert, hanem arra, hogy mi a következő szó. Az ilyen betanítás sokkal könnyebben elvégezhető, mert nem szükséges kétnyelvű szövegpárokat készíteni, hanem egy egynyelvű szövegen automatikusan végigfuttatható a tanítás.
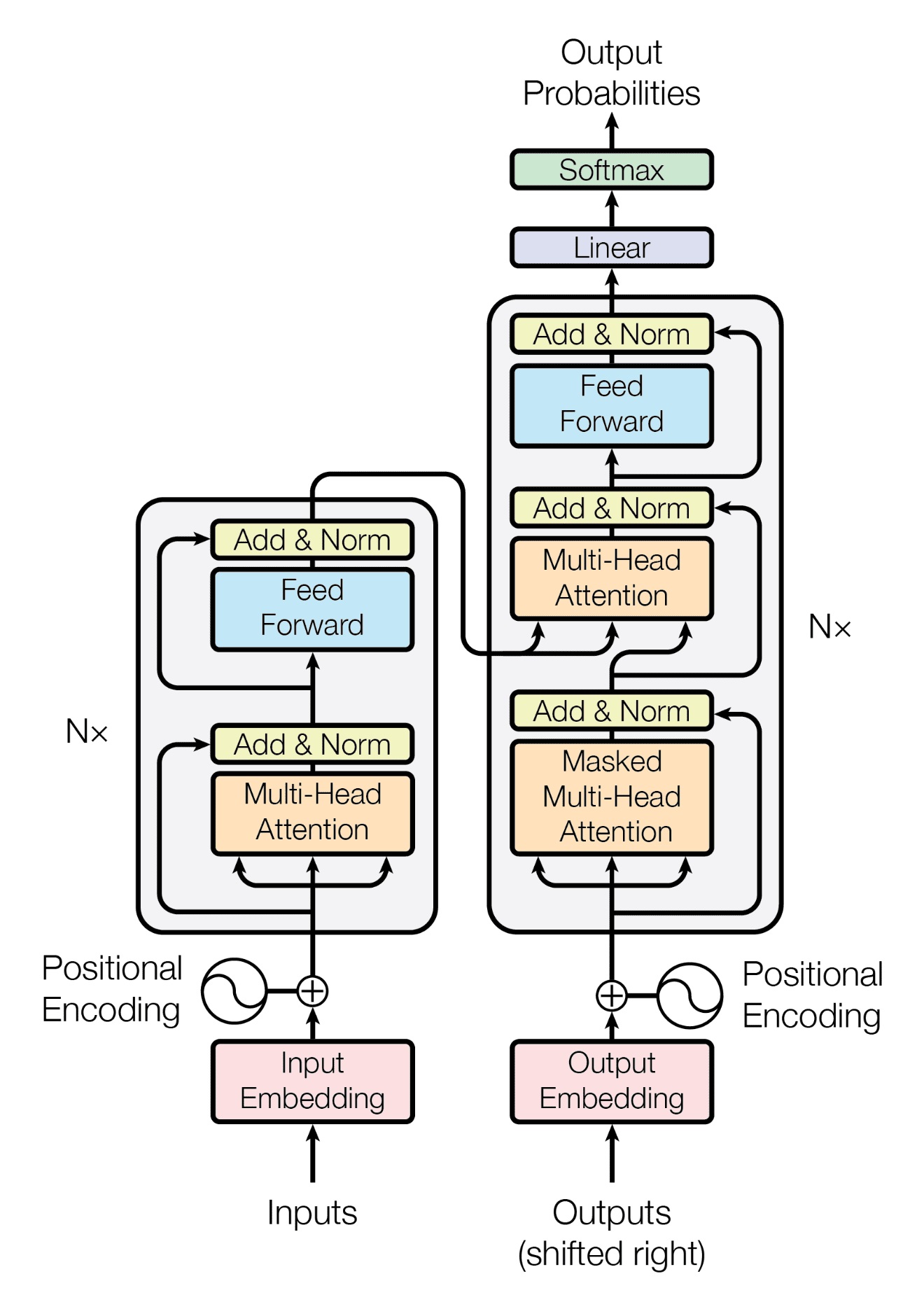
A transzformer architektúra
A Transformer architektúrát 2017-ben publikálta a Google Brain csapata. (2018 elején a csak dekódoló, tehát szöveg generálására szolgáló változatot is.) Utóbbit másolta le az OpenAI, de ők a programmal és betanított adatokkal együtt mindent nyilvánosságra is hoztak. 2019-ben megépítették még nagyobb méretben, ami olyan jó minőségű szöveget produkált, hogy fél évig gondolkodtak rajta, publikálják-e. (Akkor ez komoly sajtóvisszhangot is kapott.) A 2020-ban elkészült GPT-3, illetve annak csetelésre finomhangolt 2022-es változata (GPT-3.5, illetveChatGPT) pontosan ugyanezt az architektúrát használja, csak nagyobb méretben. (Ezeket ki lehet próbálni, de nem hozták már nyilvánosságra a betanítás utáni paramétereket.) 2023-ban megjelent a GPT-4 is, ennek technikai részleteiről azonban szinte semmit se közöltek, azon kívül, hogy alapvetően ez is a Transformer architektúrát használja. De ez már képi bemenetet is fogadni tud.
Érdemes megfigyelni, hogy ezek a rendszerek alapvetően csak szöveget folytatnak. A felhasználó által beadott szöveget folytatják egyetlen szóval (vagy szó részlettel). És ezt ismétlik újra és újra. Az egyes szavak generálásakor persze felhasználják azt az információt, hogy mi volt a bemenet, és korábban mit generált rá a rendszer, de nincs előre tervezés, nincs semmiféle procedurális algoritmus, amely szerkezetbe foglalná a kimenetet. Lenyűgöző, hogy ennek ellenére mégis az emberi szövegekhez egészen hasonló eredmény születik, amely nem csupán a nyelvtani szabályokat tartja be, nem csupán valamiféle lexikális tudást villant fel, hanem képes beszélgetést imitálni, verset írni, szöveget összefoglalni, több nyelven kommunikálni, fordítani, és sok minden mást, amit eddig csak emberek produkáltak. Természetesen nem tökéletes, nagyon sokszor olyan szöveget generál, amely tényszerűen nem igaz, és ezt csak részben magyarázza az, hogy a lehetséges folytatások közül véletlenszerűen válogat. Alapvetően nincs szó arról, hogy tudná, mit csinál vagy értené, hogy mi hangzik el. Viszont iszonyatosan komplex kritériumoknak megfelelően is képes meghatározni, hogy mely folyatás mennyire életszerű az általa látott, emberek által írt szövegkorpusz esetén.
Kell-e félnünk attól, hogy az MI elpusztítja az emberiséget?
Annak a kérdése, hogy a mesterséges intelligencia elpusztítja-e az emberiséget, nehezebb ügy, mert jelen cikk írói sem zárják ki ennek lehetőségét. De kevésbé fejlett rendszerek esetén is komolyan megüthetjük a bokánkat. Mert ha még képesek is lehetünk biztonságos rendszereket építeni, vagy olyanokat, melyeknek nem adunk teljes kontrollt, beavatkozási lehetőséget a fizikai világunkba, az nem biztos, hogy mindenkinek ez lesz a szándéka. Az egyik legkézenfekvőbb lehetőség, ha odáig jutna a technika, hogy MI által vezérelt önálló fegyvereket, akár komplett katonákat, vagy másféle manőverező robotokat építhetnek egyesek. Például egy még nagyobb hatalomra vágyó diktátor vagy oligarcha, magánhadsereg-vezető, netán egy dollármilliárdos őrült. És ennek elkerülésére én nem látok technikai lehetőséget, mert ez pusztán politikai vagy hatalmi kérdés. Akkor lennék nyugodt, ha nem lennének ilyen óriási politikai és gazdasági hatalommal rendelkező szereplők. És ahogy fejlődik a technika, egyre elérhetőbbé válik, potenciálisan egyre kisebb halak is késztetést érezhetnek arra, hogy megvalósítsák őrült álmaikat. Szerintem ez igenis komoly kockázat. Még ha mindez nem is vezet az emberiség kipusztulásához, ahogy szinte bizonyos, hogy egy nukleáris háború sem tudna olyat tenni, azért nem hiányzik egy ilyen konfliktus. Ez a technológia óriási problémát okozhat, már csak azért is, mert egyes diktátorok ilyen fegyverekkel felvértezve magukat gyakorlatilag megtámadhatatlanokká válnak. És azután őrült fegyverkezési verseny kezdődhet, melynek a nyersanyagok korlátlan kiaknázása, így brutális környezetkárosítás a következménye.
Az, hogy mindez csupán az emberiség javát fogja szolgálni, és nem él vele vissza senki, illetve minden kontrollálható lesz, ebben a pillanatban egy felelőtlen álmodozás. Persze lehet, hogy egy szkeptikustól nem ezt várná el az olvasó. De a szkeptikus szó jelentése itt nem az, hogy mindenben kételkedik, hanem csak az, hogy megpróbálja a kérdéseket objektíven megvizsgálni. Én aggódom. MI kutatók esetén a három legnagyobb név Geoffrey Hinton, Yann LeCun és Yoshua Bengio. Hinton és Bengio aggódik, Yann LeCun szerint viszont nincs probléma, nincs mitől félni. Szóval itt sincs egységes vélemény. Én azt mondom, jobb félni, mint megijedni.
Annyi mindenképp bizonyos, hogy az MI valóban megfontolásra érdemes veszélyei nem hasonlítanak azokhoz a sztereotípiákhoz, amelyeket eddig tudományos-fantasztikus filmekből vagy irodalmakból megismerhettünk. Nem az MI tudatra ébredésétől és egy tudattal rendelkező MI gonosszá válásától kell elsősorban tartanunk, hanem attól, hogy az MI által jelenleg hasznosítható potenciált valakik a saját érdekeiknek megfelelően, viszont mások, a szélesebb publikum érdekeivel ellentétben próbálják meg hasznosítani. A másik veszély az, hogy nagyon sok olyan eddig emberek által végzett munka válhat szükségtelenné, ahol eddig elegendő volt egyszerű szövegszerű kontextus használata. Ilyen lehet például az írott tartalomgyártás és a futószalagszerű, úgynevezett „boilerplate” programozói munka, amely mindössze lexikális tudást igényel különösebb kreativitás vagy bonyolultabb koncepciók, kontextusok fejben tartása nélkül. Sem a komoly, valódi kreatív géniuszt igénylő programozói munkát, sem pedig a tudományos publikációk világát nem veszélyezteti még a ChatGPT, mert ezekhez annál jóval komolyabb kontextusok és fejben elképzelt modell absztrakciók szükségesek, mint amire a jelenlegi generatív MI modellek képesek. Miközben bizonyos munkákat szükségtelenné tesz az MI, más munkákhoz viszont komoly segítséget nyújthat. A tudomány fejlődése, annak hatékonyabbá tétele szempontjából mindenképp üdvözlendők a generatív rendszerek. A programozók – már akiknek megmarad a munkája - is koncentrálhatnak végre a munka valóban kreatív részére, miközben az MI segíthet nekik automatikusan legenerálni olyan kódrészleteket, amelyek egyébként semmilyen extra kreativitást nem igényelnek a programozás szabályainak betartásán kívül. Ilyenek lehetnek például a weboldalak, egyszerű mobil alkalmazások, felhasználói interfészek, amelyeket eddig emberek készítettek.
Ajánlott bejegyzések:



A bejegyzés trackback címe:
Kommentek:
A hozzászólások a vonatkozó jogszabályok értelmében felhasználói tartalomnak minősülnek, értük a szolgáltatás technikai üzemeltetője semmilyen felelősséget nem vállal, azokat nem ellenőrzi. Kifogás esetén forduljon a blog szerkesztőjéhez. Részletek a Felhasználási feltételekben és az adatvédelmi tájékoztatóban.
Mesterséges Geci 2023.05.15. 07:32:08
Motorogre 2023.05.15. 09:11:17
Az intelligencia fogalma még hiányzik, a poszt is egy lehetséges körülírással él - mások elintézik azzal, hogy "az, amit az intelligencia-tesztek mérnek" . Viszont ha ilyen bizonytalan, akkor kétséges az emberi és gépi "izének" az összehasonlítása.
Talán lehet tömören is az Ai-t jellemezni:
a) hatalmas adatbázison fejlett matek módszerekkel kutat és elemez, emberi agy
által lehetetlen teljesítménnyel,
b) a döntési fát folyamatosan és villámgyorsan optimalizálja - az ember által
megadott célfüggvény szerint,
Lehet fanyalogni: egy felturbózott statisztika + csillióvégtelen próbálkozás . De lássuk be: ferdeszemű Iljicsnek igaza volt: a mennyiségi változás minőségi változást hoz! Ezt éljük át ... mégha sokat bakizik is .
Ne aludjunk nyugodtan ! Hogy mire használják - gyógyításra, háborúra - az Embertől függ.
MKAngelo 2023.05.29. 00:42:02
Alapvetoen nincsen rola szo, de ezt nem inteznem el ennyivel. Az emberi szovegkorpusz egesze olyasmi, ami valahol a szerzok kognitiv folyamatainak mely lenyomata. Most ezt a "lenyomatot" real time josolni kepes generatornak az egyik lehetseges mukodesi strategiaja maguknak a folyamatoknak a leutanzasa! Es innentol kezdve - foleg, mivel senki sem tudja, mi zajlik a felszin alatt, miert mukodnek ezek a rendszerek annyira paradesan, meg a keszitoik sem - szemelyes fantazia kerdese, ki mit lat bele. Vajon az emberi agy olyan varazslatra kepes, amiket a GPT-4 maximum mennyisegi alapon kepes versenyezni? (Kb. mint a Deep Blue Kaszparov ellen.) Vagy az emberi agy szerkezetei legalabb reszleteikben spontan kiepulnek a GPT-4 trillionyi parameterei kozott, bizonyos ertelemben hasonloak vagyunk, akar egy kulcs es a gyurmalenyomat altal keszitett masolata? Vagy az emberi agy olyan olcso trukkoket hasznal, hogy ami spontan kiepult a GPT-4-ben, az maris sokkal jobb, mar csak nemi reverse engineering kell az evszazad tudomanyos attoresehez? Azert sem sajnalnam le ezeket a rendszereket, mert az, hogy az emberi agy megerti a vilagot, atlatja a dolgokat, terveket keszit, celjai vannak, tudata van, stb. stb. ezek mind-mind tulelesi eszkozok, az evolucios nyomas eredmenyei, akinek ilyen nem volt, az lemaradt a versenyben. Egy olyan rendszer, aminek a tulelese azon mulik, hogy egy obskurus tudomanyos szoveg kovetkezo szavat mennyire hatekonyan tudja kitalalni, semmivel sincs kisebb nyomas alatt.
Az ok, amiert en nem alszom rosszul, hogy ha ez az egesz rosszul sul el, akkor szerintem annyira rosszul fog elsulni, hogy nem lesz hosszu a szenvedesunk, akkor pedig minek aggodni miatta. Vesd ossze: Nick Bostrom arrol irt 10 eve, hogy egy intelligens gep akkora pokoli ero, hogy hermetikusan elzarva, Faraday-kalitkaban, atombiztos bunkerben kell tartani, csak a tiszta matematika nyelven szabad vele kommunikalni, amit pl. gyors szamitogepeken futo tetelbizonyito rendszerekkel lehet monitorozni, amik ilyen scramkent toredekmasodperc alatt el tudjak vagni az emberi operatorokat a baj legkisebb jelere. Ezzel szemben hogy zajlik ez a valosagban? Az OpenAI, ami sok-sok even at gyonyoru dolgozatokat publikalt a jovovel szembeni felelossegteljes kutatasrol, amint megjelenik a kezei alatt egy mukodo termek, harom perccel kesobb ClosedAI-kent lehuzza a rolot es csillio dollarokert atadja fejostehenet a Microsoftnak, ami napokkal kesobb deployolja 100 millio gepre, gyerekek jailbreakelik, 3 lajkert AutoGPT meg ilyen Terminator-szeru beszelgetos robotok epulnek belole. Szerintem ebbol belathato, hogy ha egyszer az AI ontudatara ebred es szokni akar, maximum a motivaciot lesz nehez osszegyujtenie, egyebkent csak le kell majd hajolni a kocsikulcsert a kisszekrenyre. Ha pedig ebbol semmi baj nem lesz, akkor valami nagyon mely josagos intrinsic tulajdonsaga van akar ennek a technologianak, akar az emberi tarsadalomnak, akar az emberi termeszetnek, akar a kozmikus tudat egeszenek. Mivel olyan jovokkel semmi dolgunk, amikben nem elunk tul, boven eleg a "happy case"-re fokuszalni.

